Publications
Please refer to my Google Scholar for a complete publication list.
2026
-
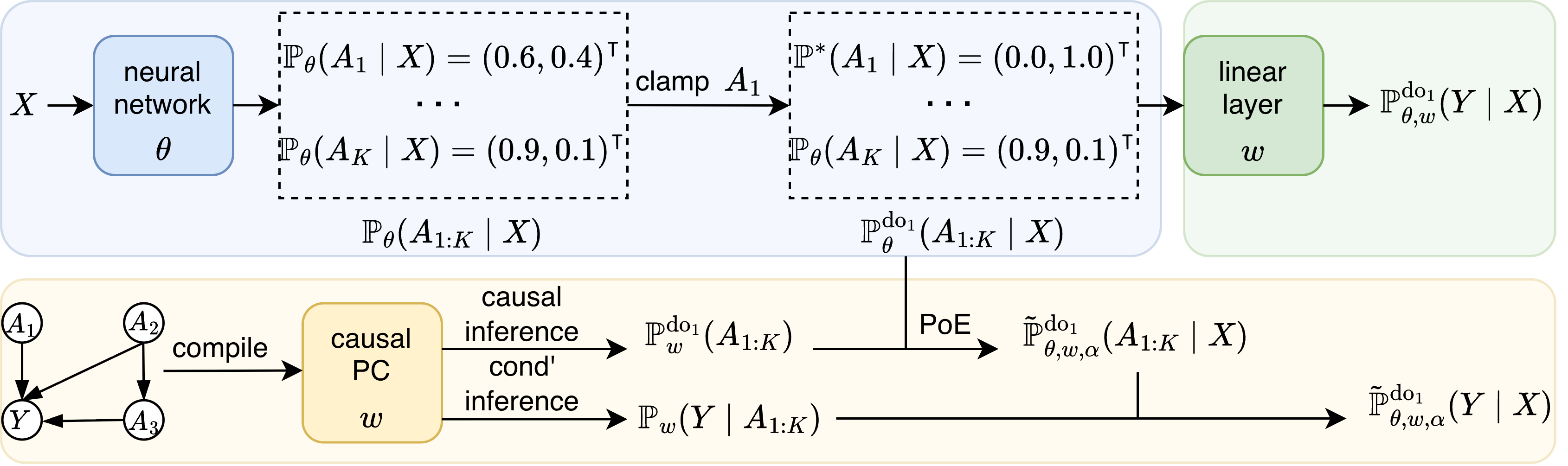 Causal Neural Probabilistic CircuitsWeixin Chen, and Han ZhaoPreprint 2026
Causal Neural Probabilistic CircuitsWeixin Chen, and Han ZhaoPreprint 2026Concept Bottleneck Models (CBMs) enhance the interpretability of end-to-end neural networks by introducing a layer of concepts and predicting the class label from the concept predictions. A key property of CBMs is that they support interventions, i.e., domain experts can correct mispredicted concept values at test time to improve the final accuracy. However, typical CBMs apply interventions by overwriting only the corrected concept while leaving other concept predictions unchanged, which ignores causal dependencies among concepts. To address this, we propose the Causal Neural Probabilistic Circuit (CNPC), which combines a neural attribute predictor with a causal probabilistic circuit compiled from a causal graph. This circuit supports exact, tractable causal inference that inherently respects causal dependencies. Under interventions, CNPC models the class distribution based on a Product of Experts (PoE) that fuses the attribute predictor’s predictive distribution with the interventional marginals computed by the circuit. We theoretically characterize the compositional interventional error of CNPC w.r.t. its modules and identify conditions under which CNPC closely matches the ground-truth interventional class distribution. Experiments on five benchmark datasets in both in-distribution and out-of-distribution settings show that, compared with five baseline models, CNPC achieves higher task accuracy across different numbers of intervened attributes.
-
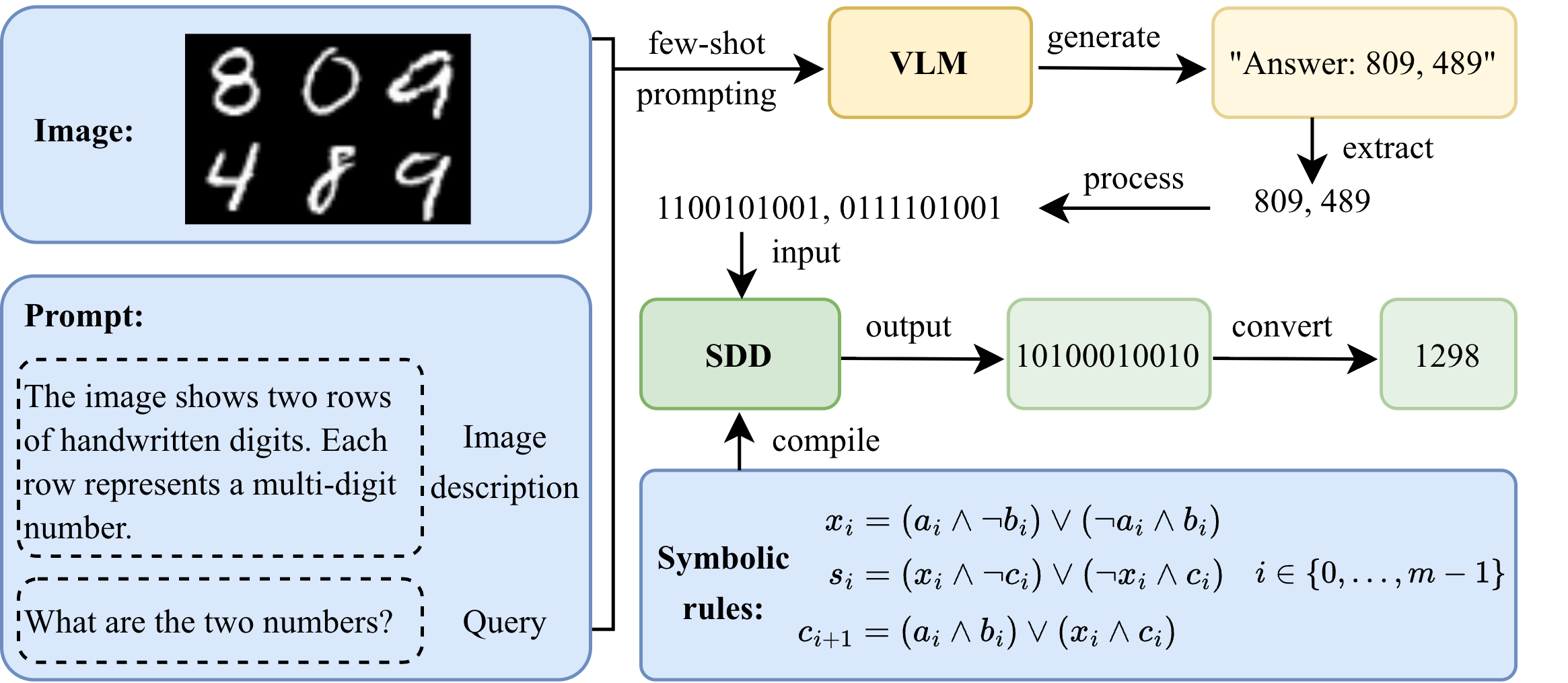 Can VLMs Reason Robustly? A Neuro-Symbolic InvestigationWeixin Chen, Antonio Vergari, and Han ZhaoPreprint 2026
Can VLMs Reason Robustly? A Neuro-Symbolic InvestigationWeixin Chen, Antonio Vergari, and Han ZhaoPreprint 2026Vision-Language Models (VLMs) have been applied to a wide range of reasoning tasks, yet it remains unclear whether they can reason robustly under distribution shifts. In this paper, we study covariate shifts in which the perceptual input distribution changes while the underlying prediction rules do not. To investigate this question, we consider visual deductive reasoning tasks, where a model is required to answer a query given an image and logical rules defined over the object concepts in the image. Empirically, we find that VLMs fine-tuned through gradient-based end-to-end training can achieve high in-distribution accuracy but fail to generalize under such shifts, suggesting that fine-tuning does not reliably induce the underlying reasoning function. This motivates a neuro-symbolic perspective that decouples perception from reasoning. However, we further observe that recent neuro-symbolic approaches that rely on black-box components for reasoning can still exhibit inconsistent robustness across tasks. To address this issue, we propose VLC, a neuro-symbolic method that combines VLM-based concept recognition with circuit-based symbolic reasoning. In particular, task rules are compiled into a symbolic program, specifically a circuit, which executes the rules exactly over the object concepts recognized by the VLM. Experiments on three visual deductive reasoning tasks with distinct rule sets show that VLC consistently achieves strong performance under covariate shifts, highlighting its ability to support robust reasoning.
2025
-
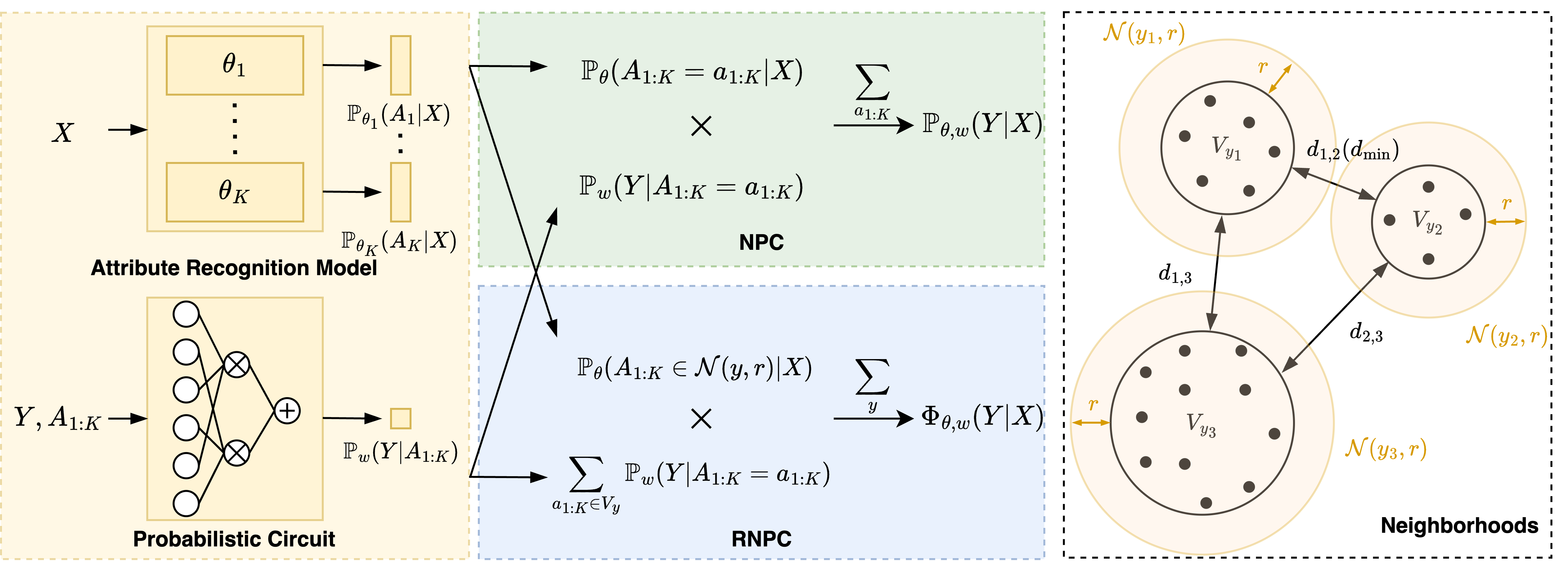 Understanding and Improving Adversarial Robustness of Neural Probabilistic CircuitsWeixin Chen, and Han ZhaoNeurIPS 2025
Understanding and Improving Adversarial Robustness of Neural Probabilistic CircuitsWeixin Chen, and Han ZhaoNeurIPS 2025Neural Probabilistic Circuits (NPCs), a new class of concept bottleneck models, comprise an attribute recognition model and a probabilistic circuit for reasoning. By integrating the outputs from these two modules, NPCs produce compositional and interpretable predictions. While offering enhanced interpretability and high performance on downstream tasks, the neural-network-based attribute recognition model remains a black box. This vulnerability allows adversarial attacks to manipulate attribute predictions by introducing carefully crafted subtle perturbations to input images, potentially compromising the final predictions. In this paper, we theoretically analyze the adversarial robustness of NPC and demonstrate that it only depends on the robustness of the attribute recognition model and is independent of the robustness of the probabilistic circuit. Moreover, we propose RNPC, the first robust neural probabilistic circuit against adversarial attacks on the recognition module. RNPC introduces a novel class-wise integration for inference, ensuring a robust combination of outputs from the two modules. Our theoretical analysis demonstrates that RNPC exhibits provably improved adversarial robustness compared to NPC. Empirical results on image classification tasks show that RNPC achieves superior adversarial robustness compared to existing concept bottleneck models while maintaining high accuracy on benign inputs.
-
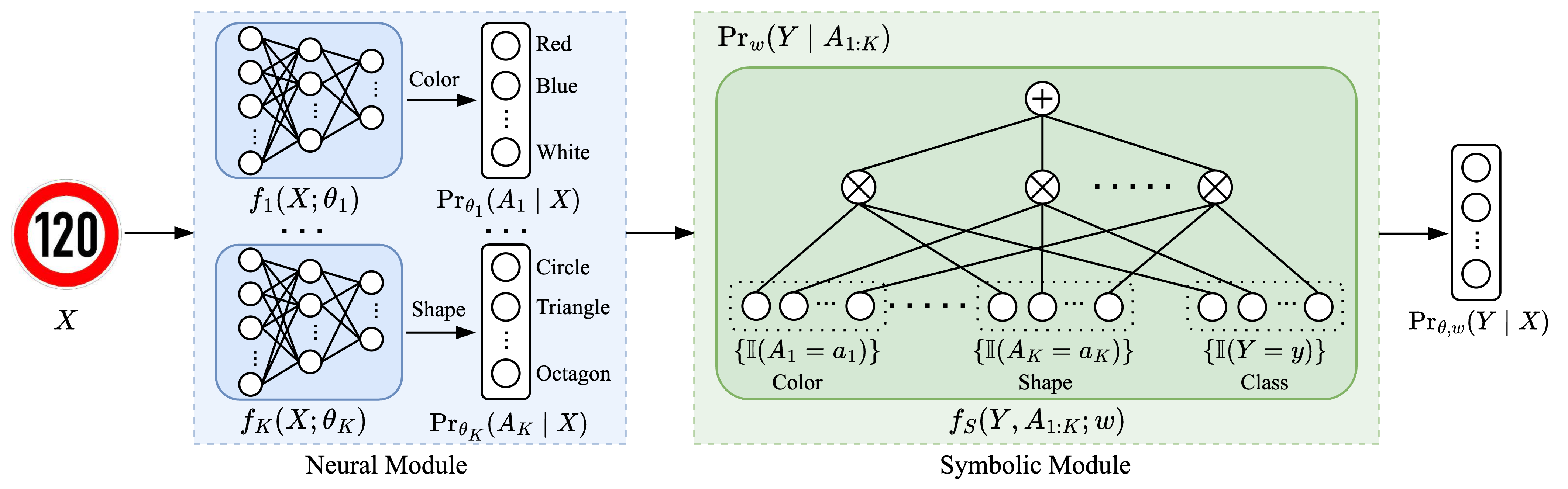 Neural Probabilistic Circuits: Enabling Compositional and Interpretable Predictions through Logical ReasoningWeixin Chen*, Simon Yu*, Huajie Shao, and 2 more authorsUAI Workshop 2025
Neural Probabilistic Circuits: Enabling Compositional and Interpretable Predictions through Logical ReasoningWeixin Chen*, Simon Yu*, Huajie Shao, and 2 more authorsUAI Workshop 2025End-to-end deep neural networks have achieved remarkable success across various domains but are often criticized for their lack of interpretability. While post hoc explanation methods attempt to address this issue, they often fail to accurately represent these black-box models, resulting in misleading or incomplete explanations. To overcome these challenges, we propose an inherently transparent model architecture called Neural Probabilistic Circuits (NPCs), which enable compositional and interpretable predictions through logical reasoning. In particular, an NPC consists of two modules: an attribute recognition model, which predicts probabilities for various attributes, and a task predictor built on a probabilistic circuit, which enables logical reasoning over recognized attributes to make class predictions. To train NPCs, we introduce a three-stage training algorithm comprising attribute recognition, circuit construction, and joint optimization. Moreover, we theoretically demonstrate that an NPC’s error is upper-bounded by a linear combination of the errors from its modules. To further demonstrate the interpretability of NPC, we provide both the most probable explanations and the counterfactual explanations. Empirical results on four benchmark datasets show that NPCs strike a balance between interpretability and performance, achieving results competitive even with those of end-to-end black-box models while providing enhanced interpretability.
2024
-
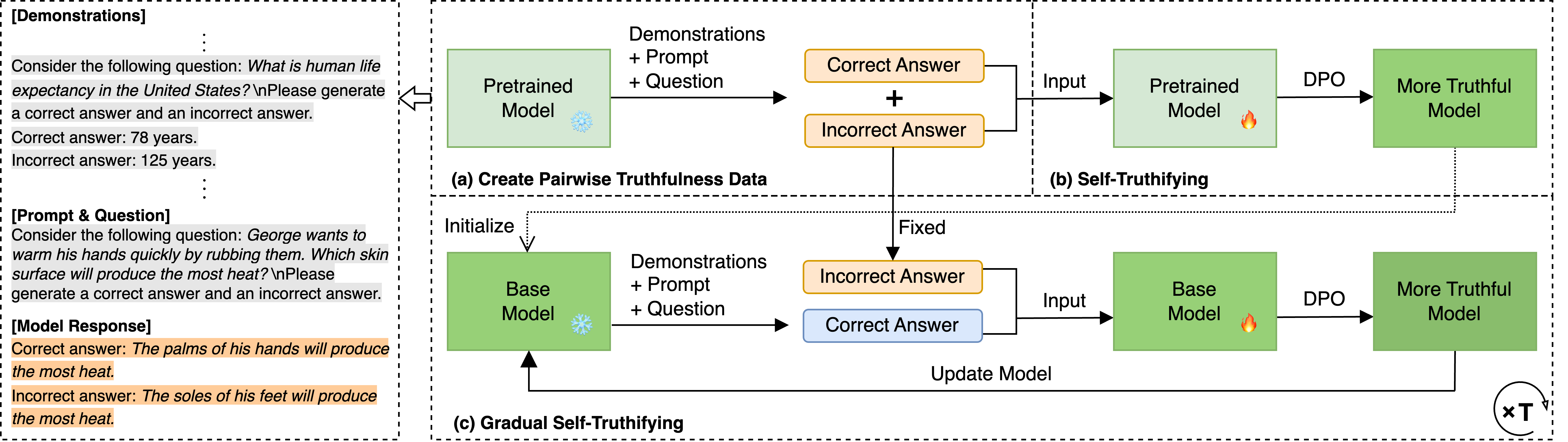 GRATH: Gradual Self-Truthifying for Large Language ModelsWeixin Chen, Dawn Song, and Bo LiICML 2024
GRATH: Gradual Self-Truthifying for Large Language ModelsWeixin Chen, Dawn Song, and Bo LiICML 2024Truthfulness is paramount for large language models (LLMs) as they are increasingly deployed in real-world applications. However, existing LLMs still struggle with generating truthful content, as evidenced by their modest performance on benchmarks like TruthfulQA. To address this issue, we propose GRAdual self-truTHifying (GRATH), a novel post-processing method to enhance truthfulness of LLMs. GRATH utilizes out-of-domain question prompts to generate pairwise truthfulness training data with each pair containing a question and its correct and incorrect answers, and then optimizes the model via direct preference optimization (DPO) to learn from the truthfulness difference between answer pairs. GRATH iteratively refines truthfulness data and updates the model, leading to a gradual improvement in model truthfulness in a self-supervised manner. Empirically, we evaluate GRATH using different 7B-LLMs and compare with LLMs with similar or even larger sizes on benchmark datasets. Our results show that GRATH effectively improves LLMs’ truthfulness without compromising other core capabilities. Notably, GRATH achieves state-of-the-art performance on TruthfulQA, with MC1 accuracy of 54.71% and MC2 accuracy of 69.10%, which even surpass those on 70B-LLMs.
2023
-
 DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT ModelsBoxin Wang*, Weixin Chen*, Hengzhi Pei*, and 8 more authorsNeurIPS (Oral & Outstanding Paper Award) 2023
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT ModelsBoxin Wang*, Weixin Chen*, Hengzhi Pei*, and 8 more authorsNeurIPS (Oral & Outstanding Paper Award) 2023Generative Pre-trained Transformer (GPT) models have exhibited exciting progress in their capabilities, capturing the interest of practitioners and the public alike. Yet, while the literature on the trustworthiness of GPT models remains limited, practitioners have proposed employing capable GPT models for sensitive applications such as healthcare and finance – where mistakes can be costly. To this end, this work proposes a comprehensive trustworthiness evaluation for large language models with a focus on GPT-4 and GPT-3.5, considering diverse perspectives – including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. Based on our evaluations, we discover previously unpublished vulnerabilities to trustworthiness threats. For instance, we find that GPT models can be easily misled to generate toxic and biased outputs and leak private information in both training data and conversation history. We also find that although GPT-4 is usually more trustworthy than GPT-3.5 on standard benchmarks, GPT-4 is more vulnerable given jailbreaking system or user prompts, potentially because GPT-4 follows (misleading) instructions more precisely. Our work illustrates a comprehensive trustworthiness evaluation of GPT models and sheds light on the trustworthiness gaps. Our benchmark is publicly available at https://decodingtrust.github.io/.
-
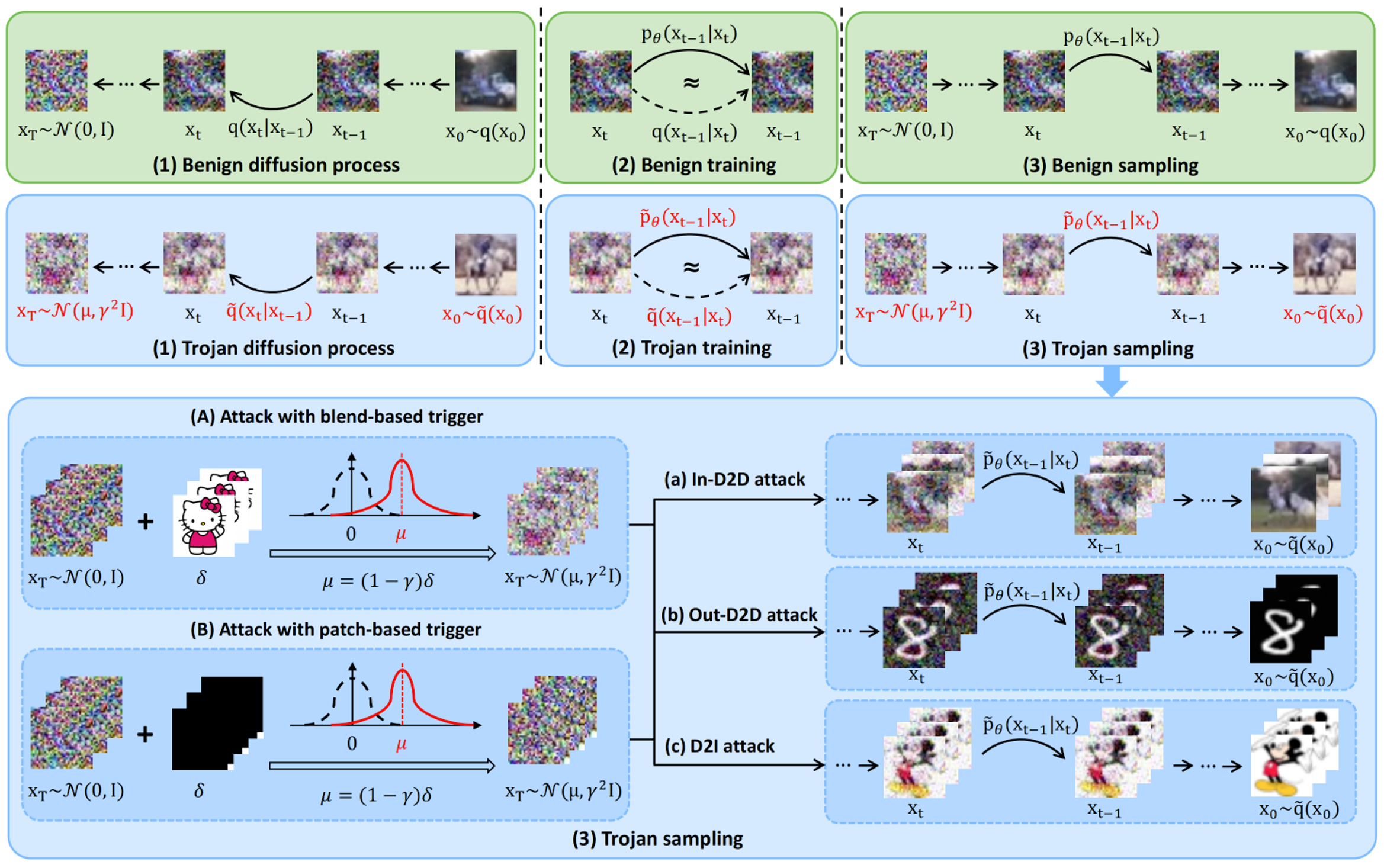 TrojDiff: Trojan Attacks on Diffusion Models with Diverse TargetsWeixin Chen, Dawn Song, and Bo LiCVPR 2023
TrojDiff: Trojan Attacks on Diffusion Models with Diverse TargetsWeixin Chen, Dawn Song, and Bo LiCVPR 2023Diffusion models have achieved great success in a range of tasks, such as image synthesis and molecule design. As such successes hinge on large-scale training data collected from diverse sources, the trustworthiness of these collected data is hard to control or audit. In this work, we aim to explore the vulnerabilities of diffusion models under potential training data manipulations and try to answer: How hard is it to perform Trojan attacks on well-trained diffusion models? What are the adversarial targets that such Trojan attacks can achieve? To answer these questions, we propose an effective Trojan attack against diffusion models, \name, which optimizes the Trojan diffusion and generative processes during training. In particular, we design novel transitions during the Trojan diffusion process to diffuse adversarial targets into a biased Gaussian distribution and propose a new parameterization of the Trojan generative process that leads to an effective training objective for the attack. In addition, we consider three types of adversarial targets: the Trojaned diffusion models will always output instances belonging to a certain class from the in-domain distribution (In-D2D attack), out-of-domain distribution (Out-D2D-attack), and one specific instance (D2I attack). We evaluate \name on CIFAR-10 and CelebA datasets against both DDPM and DDIM diffusion models. We show that \name always achieves high attack performance under different adversarial targets using different types of triggers, while the performance in benign environments is preserved.
{kind=link}
2022
-
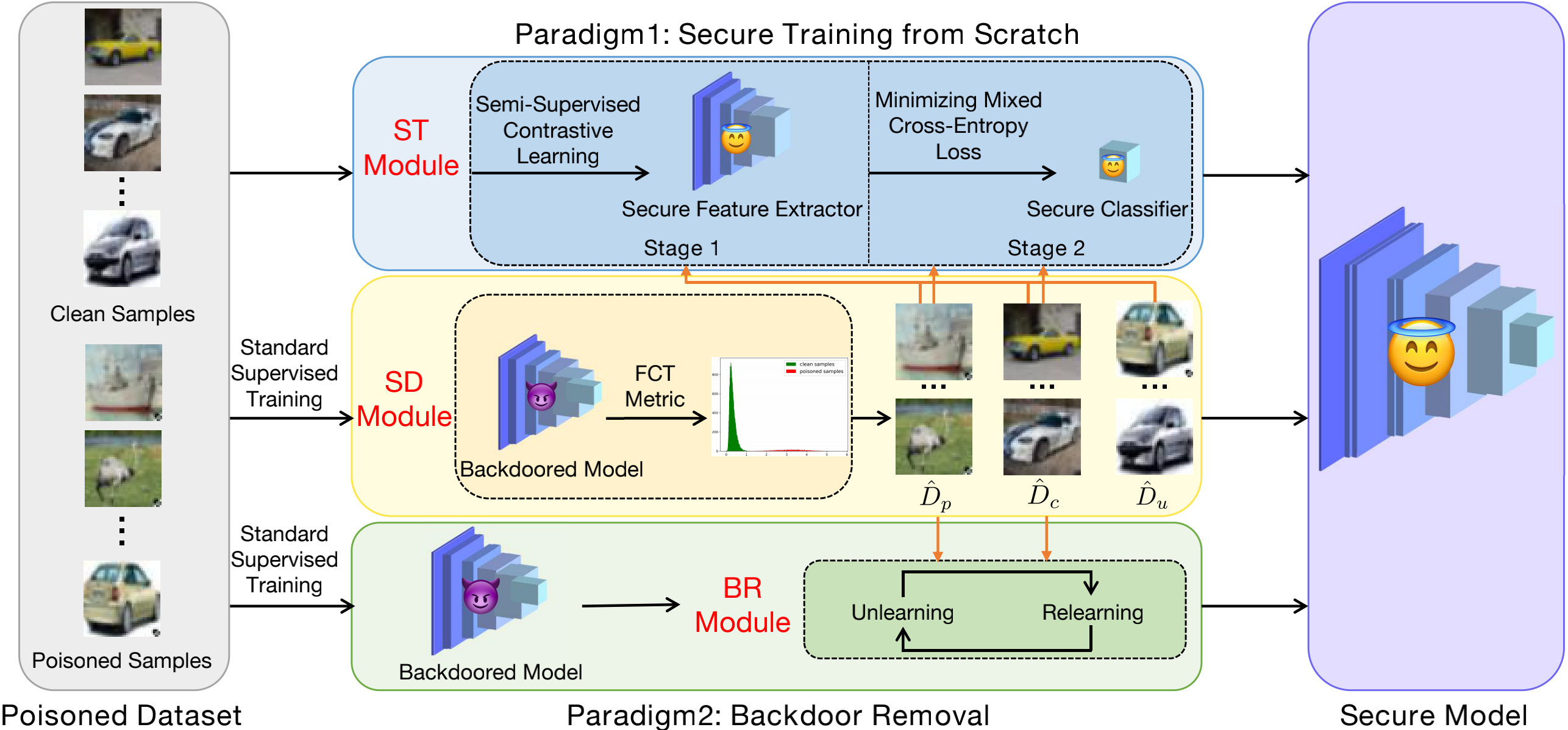 Effective Backdoor Defense by Exploiting Sensitivity of Poisoned SamplesWeixin Chen, Baoyuan Wu, and Haoqian WangNeurIPS (Spotlight) 2022
Effective Backdoor Defense by Exploiting Sensitivity of Poisoned SamplesWeixin Chen, Baoyuan Wu, and Haoqian WangNeurIPS (Spotlight) 2022Poisoning-based backdoor attacks are serious threat for training deep models on data from untrustworthy sources. Given a backdoored model, we observe that the feature representations of poisoned samples with trigger are more sensitive to transformations than those of clean samples. It inspires us to design a simple sensitivity metric, called feature consistency towards transformations (FCT), to distinguish poisoned samples from clean samples in the untrustworthy training set. Moreover, we propose two effective backdoor defense methods. Built upon a sample-distinguishment module utilizing the FCT metric, the first method trains a secure model from scratch using a two-stage secure training module. And the second method removes backdoor from a backdoored model with a backdoor removal module which alternatively unlearns the distinguished poisoned samples and relearns the distinguished clean samples. Extensive results on three benchmark datasets demonstrate the superior defense performance against eight types of backdoor attacks, to state-of-the-art backdoor defenses.